Le failover est le mécanisme qui permet de maintenir un service en fonctionnement malgré la panne d'un composant. Les clusters actif-passif et actif-actif en sont les deux grandes implémentations.
Cluster actif-passif
Configuration classique : un serveur principal (actif) traite tout le trafic, un serveur secondaire (passif) est prêt à prendre le relais. Les deux serveurs sont identiques, mais seul le principal est utilisé. En cas de panne, le secondaire s'active automatiquement en quelques secondes.
Cluster actif-actif
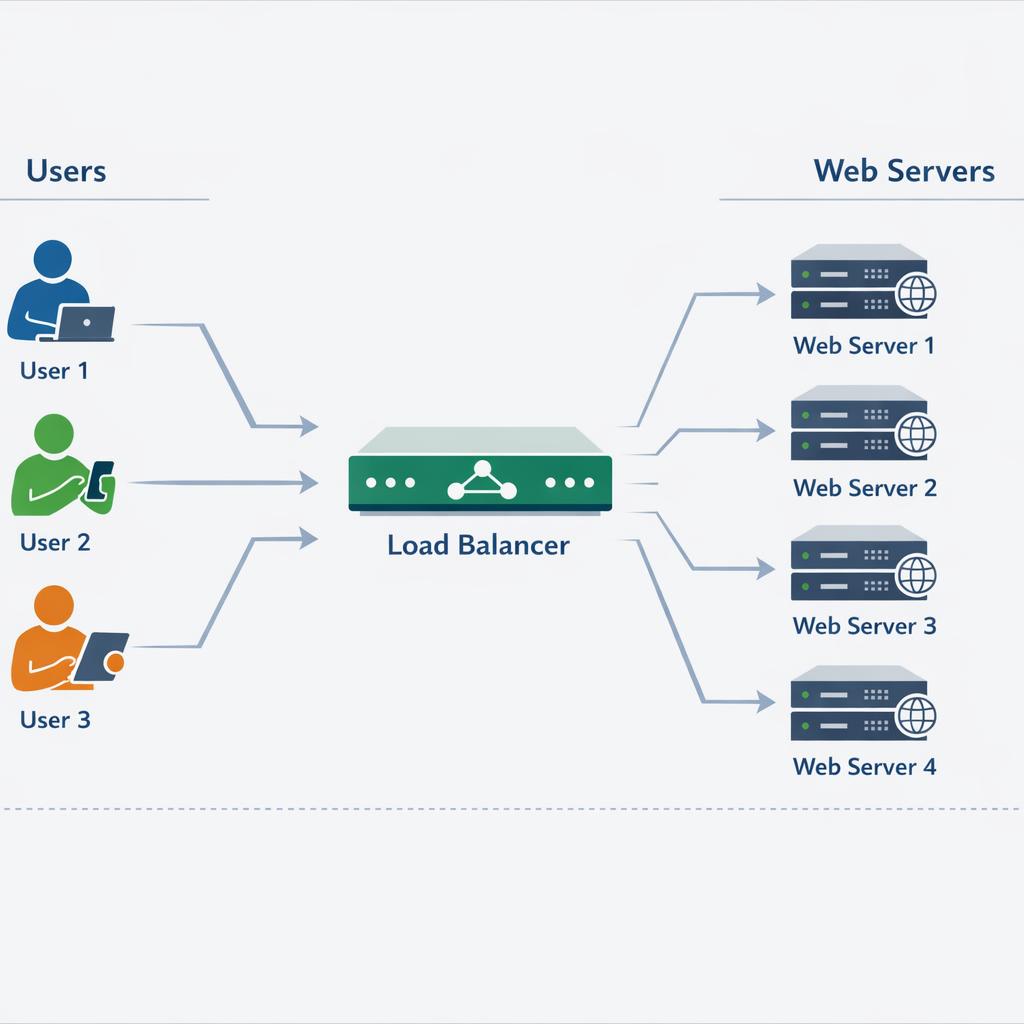
Les deux serveurs (ou plus) traitent le trafic simultanément. La charge est répartie (via load balancer) et en cas de panne d'un serveur, les autres continuent. Avantage : utilisation optimale des ressources, même en fonctionnement normal. Inconvénient : plus complexe à mettre en œuvre, nécessite une application stateless.
Le basculement automatique
Déclenché par un système de monitoring qui détecte la défaillance (heartbeat entre les nœuds, health check applicatif). Le temps de détection et de bascule (RTO — Recovery Time Objective) détermine la durée d'indisponibilité. Quelques secondes à quelques minutes selon la criticité. Voir notre article RPO, RTO et plan de reprise d'activité.
Le split brain
Le piège du cluster : si les nœuds perdent le contact entre eux mais restent actifs, chacun peut croire que l'autre est défaillant et se déclarer « actif ». Deux nœuds actifs traitent alors les données incohérentes. Les mécanismes de quorum (3 nœuds, majorité) et les dispositifs « fencing » préviennent cette situation.
La réplication de données
Pour qu'un failover fonctionne, les données doivent être synchronisées entre les nœuds. Réplication synchrone : chaque écriture est confirmée sur tous les nœuds avant de répondre (cohérence forte, latence accrue). Réplication asynchrone : écriture immédiate puis synchronisation en arrière-plan (faible latence, risque de perte en cas de panne).
Les outils disponibles
Pacemaker/Corosync pour Linux, Windows Server Failover Cluster pour Microsoft, Galera Cluster pour MySQL, Patroni pour PostgreSQL, Redis Sentinel pour Redis. Chaque écosystème a ses solutions éprouvées.
Le VRRP et l'IP flottante
Virtual Router Redundancy Protocol : plusieurs routeurs partagent une IP virtuelle, seul l'un l'annonce à un moment donné. En cas de panne du « maître », un autre prend automatiquement le relais en quelques secondes. Keepalived met en œuvre ce protocole sur Linux.
Le testing obligatoire
Un cluster non testé n'est pas fiable. Des exercices de bascule programmés — voire des tests impromptus (Chaos Engineering) — révèlent les configurations défaillantes avant qu'une vraie panne ne les expose. Netflix popularise cette approche avec Chaos Monkey.
Coût vs bénéfice
La haute disponibilité coûte : doublement des serveurs, ingénierie avancée, complexité accrue. À mesurer face à l'impact d'une indisponibilité. Pour un site commercial, le calcul est souvent favorable ; pour un blog personnel, disproportionné. Pour aller plus loin, consultez nos articles haute disponibilité et redondance et guide complet de l'hébergement.